
El Thin Content es un término con el que Google denomina al contenido que dentro de una página o url tiene poca calidad o es un contenido pobre que no aporta ningún tipo de valor para el usuario.
En muchas ocasiones el thin Content se ha asociado a tener poco contenido, pero no siempre es así, ya que depende en gran medida de la relevancia de ese contenido para los usuarios y su intención de búsqueda, ya que puedes tener una url en tu página web con un contenido escaso con pocas palabras, pero si responde bien a lo que el usuario espera encontrar, no va a ser considerado como thin content.
Es por ello que Google siempre nos pide que nos centremos en crear contenidos de calidad y nos preocupemos de ofrecer al usuario una respuesta a lo que está buscando, ya que si el usuario obtiene una solución a lo que busca seguirá usando Google como su buscador habitual.

Tipos de páginas consideradas thin content
Existen diferentes tipos de thin content que debemos tener en cuenta para poder verificar que no están presentes en nuestra web y no tener problemas con el posicionamiento de nuestra página web. Entre ellos están estos tipos de contenido pobre que veremos a continuación:
Paginas con contenido duplicado o robado
Este tipo de Thin Content que combate el algoritmo de Google Panda es uno de los más conocidos y que tienes que tener en cuenta, ya que penaliza el contenido duplicado o plagiado de otras webs que ya habían publicado ese contenido con anterioridad.
Este tipo de prácticas son unas de las más perseguidas por Google, ya que siempre quiere mostrar a los usuarios información relevante y de calidad, por lo que, si una persona ha copiado su contenido de otra web, la información que va a aportar en su web es de baja calidad, por lo que va a ser complicado que pueda llegar a posicionar y puede que Google ni rastree la web por ser considerada como thin content. Esta práctica es bastante habitual en tiendas online donde muchas veces se suben los productos directamente con el mismo contenido que facilita el distribuidor o fabricante.
También se puede producir contenido duplicado dentro de tu propia página web y que tengas varias páginas con el mismo contenido, por lo que dependiendo del motivo por el que estás generando ese contenido duplicado deberás incluir una etiqueta rel canonical para indicarle a Google cual es el contenido original para que indexe y posicione esta url o unificar ese contenido realizando una redirección.
Además de todos estos problemas que te puede generar en Google, también puedes tener problemas legales, ya que el autor original de los contenidos pueda llegar a reclamar y denunciarte.
Por todo esto, es muy importante que generes contenidos originales y de calidad que aporten información relevante de acuerdo a la intención de búsqueda que tiene el usuario, ya que a largo plazo te va a ser mucho más rentable desde todos los puntos de vista.
Contenido generado automáticamente
El contenido generado automáticamente es otro de los tipos de thin content más perseguidos por Google y que más fácilmente detectan los robots de Google.
Una de las prácticas más habituales en cuanto a contenido generado automáticamente es spinear textos, una práctica que consiste en copiar los textos y realizar ligeras variaciones a los mismos o combinando textos de diferentes webs, ya sea de manera manual o con algun programa que realice estas variaciones para intentar manipular los resultados de búsqueda en vez de ayudar a los usuarios, ya que aportan poco valor.

También se considera thin content coger un texto en otro idioma y traducirlo por una herramienta automática, incluso si hacemos dos o tres traducciones entre varios idiomas para intentar lograr un texto que parezca original.
Otro tipo de contenido generado automáticamente es por la creación de muchas tags o categorías casi vacías o por ejemplo con los filtros de búsqueda en las tiendas online.
Paginas Puerta o Doorway pages
Este tipo de practica también es perseguida por Google y consiste en la creación de páginas o landing pages con el objetivo de posicionar en los resultados de búsqueda en Google y captar tráfico como por ejemplo crear páginas orientadas a diferentes localizaciones con el mismo contenido como por ejemplo (reformas Madrid, reformas Barcelona, reformas Valencia, etc…), ya que es probable que tus servicios no sean igual de útiles para los usuarios en todas las localizaciones.
También son consideradas páginas puerta el crear diferentes páginas para palabras que son similares o sinónimos (reforma, reformar, rehabilitar etc…) para captar tráfico para luego utilizar una redirección 301 oculta que sin el consentimiento del usuario lleva al usuario a otra página más relevante de nuestra web.
En definitiva, es contar con páginas que son muy similares entre sí o que nos redirigen a otra sección de nuestra web y que no aportan ningún contenido útil ni relevante para el usuario y que solo han sido creadas con el objetivo de captar tráfico desde Google.
Páginas semivacías o vacías
Cuando nos referimos a páginas semivacías o vacías, no estamos hablando de páginas que tengan un contenido corto, ya que, aun teniendo un contenido corto, puede ser que sea un contenido de calidad que genere una respuesta útil a lo que un usuario está buscando, con lo que no sería considerado como thin content.
Si, por el contrario, en tu web o tienda online tienes descripciones de producto o de un servicio que ofreces muy escasas y que no describen bien el producto o servicio que estas vendiendo, te va a ser muy complicado aportar valor al usuario y dar respuesta a todas las dudas que tiene un usuario con esa página, además también va a ser más complicado que Google lo entienda, por lo que va a ser muy difícil que puedas llegar a posicionar para términos con potencial de búsqueda y donde la competencia trabaja mejor esos contenidos en su web.
¿Cómo afecta y qué consecuencias tiene el thin content en una web?
Contar con este tipo de contenido en tu web, ya sea por cualquiera de los tipos de thin content que hemos visto, puede llevarte a una penalización por el algoritmo de Google, donde verás como poco a poco vas perdiendo visibilidad y tráfico en tu web hasta llegar a un punto donde podrás llegar a perder todas las visitas a tu web que se producen gracias al tráfico orgánico a través de Google. También es posible que Google desindexe tu web.
Este tipo de penalización no va a ocurrir a menos que tengas un porcentaje bastante elevado de urls en tu web con thin content, como puede ser webs donde la mayoría de sus contenidos son plagiados de otras páginas o generados automáticamente mediante programas o son webs donde la mayoría de los contenidos no aportan nada de valor o son copiados del distribuidor por ejemplo como suele ocurrir en muchas tiendas online.
Si por el contrario, únicamente tienes un porcentaje bajo de páginas con thin content en tu web y las corriges en tu web, va a ser positivo para tu web, no solo para Google, sino también para mejorar la experiencia de usuario en nuestra web y mejorar el enlazado interno y link juice interno de nuestra web, aunque es probable que no vayas a notar un cambio muy grande en la visibilidad y posicionamiento de tu página web.
Para webs muy grandes que cuentan con miles de urls, tener un porcentaje de urls con thin content le puede afectar al crawl budget o presupuesto de rastreo que Google asigna a tu web, ya que si Google empieza a rastrear muchas urls sin contenido o con poco contenido que no aporta valor, el presupuesto que te asigna va a ser menor, con lo que dificulta la visibilidad y posicionamiento de tu web en Google.
¿Cómo detectar el thin content?
Después de ver todos los tipos de thin content que puedes tener en una web, es importante conocer como puedes detectarlo para evitar tener urls en tu web con contenido duplicado o con poco valor para tus usuarios.
Existen varias herramientas con las que analizar tu página web y con las que podrás detectar en que páginas tienes thin content en tu web y que son las siguientes:
Google Search Console
Es una herramienta gratuita de Google que ayuda a los propietarios de sitios web a conocer el rendimiento de su página web en Google.
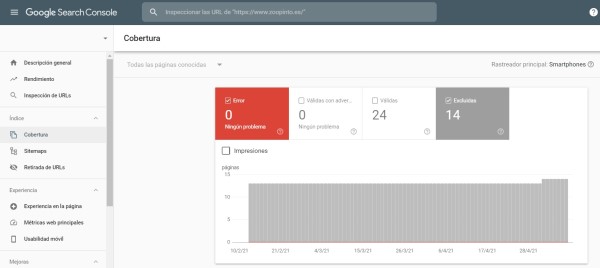
Una de las opciones que podemos ver son las urls que nos marca Google Search Console desde el informe de cobertura y que aparecerán marcadas como:
- Duplicada: la URL enviada no se ha seleccionado como canónica
- Se ha retirado la página por una reclamación legal
- Duplicada: Google ha elegido una versión canónica diferente a la del usuario
- Duplicada: el usuario no ha indicado ninguna versión canónica
- Rastreada: actualmente sin indexar
Screaming Frog
Es una herramienta que tenemos que descargar en nuestro ordenador y que va a rastrear toda nuestra web. Una de las funciones que tiene esta herramienta, nos va a detectar todas las urls con elementos duplicados como titles, meta descriptions, H1, etc… También nos puede indicar todas las urls que tienen poco contenido para que podamos analizar y ver si es un problema en nuestra web.
Es una herramienta de pago, aunque tiene una opción gratuita que nos permite rastrear hasta 500 urls por dominio.
SemRush
Otra herramienta de pago que podemos utilizar para detectar thin content en nuestra web es SemRush. Entre las muchas funciones que tiene esta herramienta, podemos utilizar dentro de la herramienta las funciones de Content Analyzer o el Site Audit para analizar toda nuestra web y que nos indique que errores ha detectado como por ejemplo páginas con meta descripciones duplicadas, páginas con titles o h1 duplicados, páginas con poco texto en relación al html o páginas con pocas palabras.
CopyScape
Es una herramienta online que analiza los textos de tu página web para detectar textos duplicados en otras páginas web, por lo que te puede ayudar a identificar las urls que tienes con contenidos copiados de otras webs.

Siteliner
Es otra herramienta online que analiza tu página web que te ayuda a descubrir el porcentaje de contenidos duplicados por url dentro de tu web. Tiene una versión gratuita que te permite analizar sitios web con hasta 250 páginas y una versión premium para analizar webs con hasta 25.000 urls.

¿Cómo evitar y solucionar el thin content en tu web?
Una vez que hayamos detectado todo el thin content que tenemos en nuestra web y conozcamos los motivos por los que se está produciendo este problema podemos comenzar a solucionar este problema de nuestra web.
Redireccionar urls con thin content y unificar contenidos
Una de las soluciones que podemos emplear es incluir un redireccionamiento 301 a las urls que están duplicadas en nuestra web hacia las urls homónimas correspondientes que están mejor posicionadas. Si tienen contenido pobre y no tienen una url homónima podemos redirigir a otra url de temática similar.
Esta opción es recomendable si las urls que vamos a redirigir tienen enlaces entrantes que no queremos perder.
Mejorar los textos que tenemos
Una de las mejores opciones que tenemos para solucionar el thin content es mejorar los contenidos de las urls de nuestra web que no hemos trabajado, aportando valor para un usuario en cada una de las páginas de nuestra web y adatándolo siempre a la intención de búsqueda de los usuarios.
Por ejemplo, si tenemos una tienda online y todas las descripciones de producto han sido copiadas del fabricante, tendremos que ir creando contenidos originales propios que aporten valor al usuario que está buscando esos productos.
Bloquear el contenido y no indexarlo
En ocasiones en nuestra web, tenemos que tener ciertos contenidos por algún motivo en específico, por lo que, en esos casos, la mejor solución es evitar que Google pueda rastrear e indexar estas urls de tu página web.
Para ellos podemos emplear el archivo robots.txt, donde le indicaremos a los robots que directorios o páginas no queremos que pueda rastrear con el objetivo de que no las pueda indexar. Si ya tenemos las urls indexadas en Google o tiene acceso el robot desde un enlace en una página indexada, tenemos primero que desindexarlas desde Google Search Console o poner una etiqueta noindex, que evitará que se indexe esa página cuando Google vuelva a rastrear la web.
Uso de Canonicals
Otra de las opciones que tenemos cuando es necesario tener dos páginas con un contenido casi idéntico es emplear la directiva rel=canonical, donde le indicamos a Google que página debe posicionarse para que Google le de mayor prioridad.
Eliminar Contenidos con thin content
Si no podemos realizar ninguna de las otras opciones, solo nos queda eliminar ese contenido de baja calidad que tenemos en nuestra web para eliminar este problema.
